ECS上のGoアプリケーションでAWS X-RayとOpenTelemetryを使って分散トレーシングを実現する
マイクロサービスアーキテクチャを採用すると、リクエストが複数のサービスを横断することが一般的になり、パフォーマンスのボトルネック特定やエラー追跡が複雑になります。
この課題を解決するのが「分散トレーシング」です。
この記事では、Amazon ECS (Elastic Container Service) 上で動作するGoアプリケーションに、OpenTelemetry (Otel) を導入し、AWS X-Ray でトレースを可視化する具体的な方法を解説します。
OpenTelemetryを利用することで、特定のベンダーにロックインされることなく、標準化された方法でトレーシングを実現できるのが大きなメリットです。
アーキテクチャ概要
今回構築するシステムの構成は以下の通りです。

- Go Application Container: OpenTelemetry SDK for Goを組み込み、リクエストのトレース情報を生成します。
- AWS Otel Collector Sidecar Container: アプリケーションコンテナと同じタスク内で動作するサイドカーです。アプリケーションからOtel Protocol (OTLP) 経由でトレース情報を受け取ります。
- AWS X-Ray: Otel Collectorがトレース情報をX-Rayフォーマットに変換し、AWS X-Rayサービスに送信します。これにより、トレースデータをコンソールで可視化・分析できます。
アプリケーションは localhost に対してトレースを送信するだけでよく、CollectorがAWSとの通信をすべて担ってくれるため、アプリケーションコードをシンプルに保てます。
ステップ1: AWS Otel Collectorサイドカーの設定
まず、ECSタスク定義にAWS Otel Collectorをサイドカーとして追加します。アプリケーションコンテナの定義に加えて、以下のコンテナ定義を追加してください。
ポイントは、環境変数 AOT_CONFIG_CONTENT を使ってCollectorの設定をインラインで記述している点です。これにより、設定ファイルを別途管理する必要がなくなり、タスク定義だけで完結します。
{ "name": "aws-otel-collector", "image": "public.ecr.aws/aws-observability/aws-otel-collector:latest", "cpu": 32, "memory": 256, "essential": true, "portMappings": [ { "containerPort": 4317, "protocol": "tcp" } ], "environment": [ { "name": "AWS_REGION", "value": "ap-northeast-1" }, { "name": "AOT_CONFIG_CONTENT", "value": "receivers:\n otlp:\n protocols:\n grpc:\n endpoint: 0.0.0.0:4317\n\nexporters:\n awsxray:\n region: ap-northeast-1\n\nservice:\n pipelines:\n traces:\n receivers: [otlp]\n exporters: [awsxray]" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/my-app-log-group", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "otel-collector" } } }
Collector設定の解説
- receivers:
- exporters:
- データの送信設定です。awsxray エクスポーターを使い、指定されたリージョン (ap-northeast-1) のX-Rayにデータを送信します。
- service.pipelines:
- receivers と exporters を繋ぐパイプラインを定義します。traces パイプラインで、otlp で受け取ったデータを awsxray に流します。
✅ 重要: このコンテナがX-Rayにデータを送信できるよう、ECSタスクロールに AWSXRayDaemonWriteAccess のIAMポリシーをアタッチするのを忘れないでください。
ステップ2: Goアプリケーション側のOpenTelemetry設定
次に、Goアプリケーション側でOpenTelemetry SDKをセットアップします。ここでは、Connectフレームワーク (connect-go) を利用している例で説明します。
トレーサープロバイダーの初期化
まず、トレース情報のエクスポーターやサービス名などのリソース情報を設定するトレーサープロバイダーを作成します。この処理を独立した trace パッケージにまとめておくと便利です。
package trace import ( "context" "time" "go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc" "go.opentelemetry.io/otel/sdk/resource" "go.opentelemetry.io/otel/sdk/trace" semconv "go.opentelemetry.io/otel/semconv/v1.4.0" ) const ( // ここで設定したサービス名がX-Rayのサービスマップに表示される serviceName = "user-service" ) // NewTracerProvider は新しいTracerProviderを生成します func NewTracerProvider(ctx context.Context, opts ...otlptracegrpc.Option) (*trace.TracerProvider, error) { // オプションが渡されない場合、トレーシングは無効 (No-op) if len(opts) == 0 { return trace.NewTracerProvider(), nil } // OTLP/gRPCエクスポーターを作成 traceExporter, err := otlptracegrpc.New(ctx, opts...) if err != nil { return nil, err } // サービス名などのリソース情報を定義 rsc, err := resource.New(ctx, resource.WithAttributes( semconv.ServiceNameKey.String(serviceName), ), ) if err != nil { return nil, err } rsc, err = resource.Merge(resource.Default(), rsc) if err != nil { return nil, err } // トレーサープロバイダーを構成 traceProvider := trace.NewTracerProvider( trace.WithBatcher(traceExporter, // デフォルトは5秒。デモのため1秒に設定 trace.WithBatchTimeout(time.Second)), trace.WithResource(rsc), ) return traceProvider, nil }
アプリケーション起動時の設定
アプリケーションの起動時に、環境変数などから設定を読み込み、トレーサープロバイダーをセットアップしてグローバルに登録します。
環境変数 TRACE_ENDPOINT を使うことで、ローカル開発時などトレーシングが不要な場合に簡単に無効化できる設計になっています。
ECSで実行する際は、この環境変数に localhost:4317 を設定します。
package main import ( "context" "net/http" "github.com/bufbuild/connect-go" "go.opentelemetry.io/contrib/connect-go/otelconnect" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc" "your/app/internal/trace" // 先ほど作成したパッケージ ) func main() { // ... (設定の読み込みなど) var traceOpts []otlptracegrpc.Option // 環境変数 `TRACE_ENDPOINT` が設定されている場合のみトレーシングを有効化 // ECSではこの値に "localhost:4317" を設定する if cfg.Trace.Endpoint != "" { traceOpts = append(traceOpts, otlptracegrpc.WithEndpoint(cfg.Trace.Endpoint)) // サイドカーへの通信はコンテナ内に閉じるため、暗号化は不要 if cfg.Trace.Insecure { traceOpts = append(traceOpts, otlptracegrpc.WithInsecure()) } } // トレーサープロバイダーを作成 tp, err := trace.NewTracerProvider(context.Background(), traceOpts...) if err != nil { // ... (エラーハンドリング) panic(err) } // グローバルなトレーサープロバイダーとして設定 otel.SetTracerProvider(tp) // Connect用のOtelインターセプターを作成 otelInterceptor, err := otelconnect.NewInterceptor( otelconnect.WithTracerProvider(tp), ) if err != nil { panic(err) } // ... (サーバー起動処理) }
otelconnect.NewInterceptor を使うことで、手動でSpanを開始・終了するコードを書かなくても、ConnectのRPC呼び出しが自動的にトレースされるようになります。非常に便利ですね!
X-Rayでのトレース確認
アプリケーションをデプロイしてリクエストを送信すると、AWSマネジメントコンソールの X-Ray 画面でトレースが確認できるようになります。
- サービスマップ: リクエストの経路やレイテンシ、エラー率などが視覚的にわかります。
- トレース: 個々のリクエストの詳細なトレースを確認できます。リクエストがサービス内のどの処理にどれくらいの時間を要したかが、タイムライン(セグメント)で表示されます。
これで、パフォーマンスのボトルネックやエラーが発生した箇所を迅速に特定できます。
まとめ
OpenTelemetryとAWS Otel Collectorサイドカーを利用することで、Goアプリケーションに簡単かつ標準的な方法で分散トレーシングを導入できました。
要点:
- Otel Collectorサイドカー: アプリケーションからトレース収集のロジックを分離します。
- AOT_CONFIG_CONTENT: Collectorの設定を環境変数で完結させ、管理を簡素化します。
- Otel SDK for Go: アプリケーション内でトレースを生成します。
- Connect Interceptor: RPC呼び出しを自動で計装し、コードをクリーンに保ちます。
X-Rayを使いたいけど標準化されたOtelを使いたい場合はこのように設定すると実現できます。
ぜひあなたのアプリケーションにも導入して、オブザーバビリティを向上させてみてください!
D-Plus Tokyo #10の登壇資料
D-Plus Tokyo #10 今年はどうする?学びを進化させる生成AIの活用方法発表LT会に登壇したときの登壇資料です
unique packageでメモリ効率化
Hello Gopher!
Go 1.23で追加された新機能、uniqueパッケージをご存知ですか?
このパッケージを使えば、アプリケーションのメモリ効率を劇的に向上させることができます。
今回は、uniqueパッケージの魅力を深掘りしていこうと思います。
interningや弱参照の概念から、内部構造、使い方、そしてベンチマーク結果まで、詳しく紹介していきます!
uniqueパッケージとは?
uniqueパッケージは、Go 1.23で標準ライブラリに追加された新しいパッケージです。
このパッケージの主な目的は、メモリ使用量を削減し、比較操作を高速化することです。
どのように実現しているのでしょうか?その秘密は「interning」と「弱参照」にあります。
interningと弱参照
interning(インターニング)とは?
interningは、同じ内容を持つデータを共有することでメモリ使用量を削減する技術です。
例えば、文字列の場合、同じ内容の文字列が複数回使用されると、1つのインスタンスだけを保持し、それを参照することで重複を排除します。
具体的には以下のような利点があります:
- メモリ使用量の削減:同じデータを複数回保持する必要がなくなります。
- 比較操作の高速化:インターンされたデータは単純なポインタ比較で同一性を確認できます。
- 文字列処理の効率化:特に文字列操作が多いアプリケーションで効果を発揮します。
弱参照(Weak Reference)の役割
弱参照は、オブジェクトへの参照を保持しつつ、ガベージコレクション(GC)の対象となることを許可する特殊な参照型です。
uniqueパッケージは内部的に弱参照を使用しており、これによってメモリリークを防ぎつつ効率的なメモリ管理を実現しています。
弱参照の主な特徴:
- GCの対象になる:通常の強い参照と異なり、弱参照されているオブジェクトは他の強い参照がなくなるとGCの対象となります。
- キャッシュに最適:一時的にデータを保持したいが、メモリ圧迫は避けたい場合に有用です。
- 循環参照の回避:強い参照で起こりがちな循環参照によるメモリリークを防ぎます。
uniqueパッケージの内部実装
uniqueパッケージの内部実装は、効率的なメモリ使用と高い並行性能を実現するために、いくつかの重要な技術を採用しています。
以下に、その主要な要素を詳しく解説します。
ハッシュトライ(HashTrieMap)の実装
uniqueパッケージの中核となるデータ構造は、HashTrieMapと呼ばれる並行ハッシュ木構造です。
この構造は以下の特徴を持っています:
- 8バイトのハッシュ値を使用した適応型基数木(adaptive radix tree)の簡略化版です。
- 読み取り操作の完全な並行性を実現しています。
- 挿入と削除操作には細粒度のロック技術を使用し、競合を減少させています。
- 効率的な成長と縮小が可能で、動的なサイズ調整に適しています。
この実装により、頻繁な読み取り操作と比較的稀な書き込み操作というuniqueパッケージの使用パターンに最適化されています。
弱参照の実装
uniqueパッケージは内部的に弱参照を使用しています。具体的には:
コアデータ構造は map[any]*T に近い形で、*T が弱参照となっています。
ランタイムが *Tを完全に制御し、オブジェクトが回収された時にnilになる特殊なハンドルを付加します。
*T への参照がなくなると、GCがハンドルをクリアします。
ガベージコレクションとの連携
uniqueパッケージはガベージコレクタ(GC)と密接に連携して動作します:
GCサイクルごとに、バックグラウンドのゴルーチンがnilハンドルを持つマップエントリをクリーンアップします。
メモリの即時回収を可能にするため、弱ポインタハンドルにアクセスする前に、常にTを含むスパンが掃除されていることを確認します。
この実装により、go4.org/internパッケージが必要とする3回のGCサイクルではなく、1回のGCサイクルでメモリを回収できます。
並行性と性能最適化
uniqueパッケージは高い並行性能を実現するために、以下の最適化を行っています:
- 読み取り操作は完全に並行可能で、スケーラビリティが高いです。
- 書き込み操作(挿入と削除)は細粒度のロックを使用し、競合を最小限に抑えています。
- Make関数は、提供された値が既にマップ内に存在する場合、アロケーションを回避します。
新しい値をマップに追加する際は、明示的にクローンを作成します。
これらの最適化により、uniqueパッケージは大規模で頻繁にアクセスされるデータセットに対して特に効果的に動作します。
uniqueパッケージの使い方
uniqueパッケージの主要な型と関数は以下の通りです:
Handle[T comparable]型:比較可能な型Tの値に対する一意のハンドルを表します。Make[T comparable](value T) Handle[T]関数:値からハンドルを生成します。(h Handle[T]) Value() Tメソッド:ハンドルから元の値を取得します。
使用例:
package main import ( "fmt" "unique" ) func main() { // 文字列のinterning h1 := unique.Make("Go 1.23") h2 := unique.Make("Go 1.23") fmt.Println(h1 == h2) // true // 構造体のinterning type Version struct { Major, Minor int } v1 := unique.Make(Version{1, 23}) v2 := unique.Make(Version{1, 23}) fmt.Println(v1 == v2) // true // 元の値の取得 fmt.Println(v1.Value()) // {1 23} }
ベンチマーク結果
uniqueパッケージの性能を示すために、簡単なベンチマーク例を見てみましょう。
package main import ( "strings" "testing" "unique" ) const letters = "abcdefghijklmnopqrstuvwxyz" const repeatCount = 1_000_000 var str1, str2 string func init() { str1 = strings.Repeat(letters, repeatCount) str2 = strings.Repeat(letters, repeatCount) } func BenchmarkStringCompare(b *testing.B) { b.Run("strings-repeat", func(b *testing.B) { b.ResetTimer() s1 := strings.Repeat(letters, repeatCount) s2 := strings.Repeat(letters, repeatCount) for i := 0; i < b.N; i++ { _ = s1 == s2 } b.ReportAllocs() }) b.Run("unique", func(b *testing.B) { b.ResetTimer() handle1 := unique.Make(str1) handle2 := unique.Make(str2) for i := 0; i < b.N; i++ { _ = handle1 == handle2 } b.ReportAllocs() }) }
結果は下記でした
BenchmarkStringCompare/strings-repeat-12 1341 842679 ns/op 38779 B/op 0 allocs/op BenchmarkStringCompare/unique-12 1000000000 0.2818 ns/op 0 B/op 0 allocs/op
ベンチマーク結果を分析すると、以下のことが分かります。
- 実行時間
- strings-repeat: 2,935,067 ns/op (約2.94 ms/op)
- unique: 0.2775 ns/op
uniqueパッケージを使用した方法が約10,576,000倍高速です。これは非常に大きな差です。
- メモリ使用量
- strings-repeat: 52,002,843 B/op (約49.6 MB/op)
- unique: 0 B/op
uniqueパッケージを使用した方法ではメモリ割り当てが発生していません。
- アロケーション回数
- strings-repeat: 2 allocs/op
- unique: 0 allocs/op
uniqueパッケージを使用した比較は、通常の文字列比較よりも桁違いに高速です。
uniqueパッケージを使用した方法では追加のメモリ割り当てが発生していません。
一方、strings-repeatでは各操作で約49.6MBものメモリを使用しています。これは非常に大きな差です。
strings-repeatでは2回のアロケーションが発生していますが、uniqueパッケージではアロケーションが発生していません。
大きな文字列を頻繁に比較する場合、uniqueパッケージを使用することで劇的なパフォーマンス向上が期待できます。
メモリ使用量が重要な場合、uniqueパッケージの利点はさらに顕著になります。
ただし、文字列が頻繁に変更される場合、ハンドルの再生成コストを考慮する必要があります。
大きな文字列を繰り返し比較する場合、uniqueパッケージを使用することで劇的なパフォーマンス向上とメモリ使用量の削減が可能です。
特に、メモリ制約のあるシステムや高性能が要求されるアプリケーションでは、uniqueパッケージの利用を強く検討する価値があります。
ただし、初期化コストや使用パターンを考慮し、適切な場面で使用することが重要です。
実際の使用例と利点
uniqueパッケージは、以下のようなシナリオで特に有用です:
大規模な文字列セットのメモリ効率化
- 例:ログ処理システムでのメッセージテンプレートの管理
頻繁に比較される複雑なデータ構造の最適化
メモリ使用量の削減が重要なアプリケーション
- 例:メモリ制約のあるシステムでの大規模データセットの処理
実際の使用例として、Go標準ライブラリのnet/netipパッケージでは、IPv6のゾーン名の効率的な管理にuniqueパッケージが使用されています。
これにより、ネットワーク関連の処理で効率的なメモリ使用と高速な比較が可能になっています。
uniqueパッケージを使用する主な利点は以下の通りです:
- メモリ使用量の削減:同じ内容の値を共有することで、重複データを排除できます。
- 高速な比較:Handle同士の比較は単純なポインタ比較になるため、非常に高速です。
- 型安全性:ジェネリクスを使用しているため、型安全な実装が可能です。
- GCとの連携:内部的に弱参照を使用しているため、不要になったデータは自動的に解放されます。
まとめ
Go 1.23で導入されたuniqueパッケージは、効率的なメモリ使用を実現する強力なツールです。
内部的に最適化された並行データ構造と、ガベージコレクタとの緊密な連携により、高性能かつメモリ効率の良い実装を提供しています。
uniqueパッケージは、Go言語のエコシステムに新たな可能性をもたらす重要な追加機能です。
大規模データ処理やパフォーマンスクリティカルなアプリケーションの開発者にとって、強力な武器となることでしょう。
ぜひ、あなたのプロジェクトでuniqueパッケージを試してみてください!
最後に、uniqueパッケージの詳細な使用方法や最新の情報については、公式ドキュメントを参照することをお勧めします。
Go 1.23の新機能を存分に活用して、より効率的で高性能なアプリケーションを開発しましょう!
参考情報
開発生産性と Security Shift Left
社内LTで使用したスライドです
いまさらだけどTeam Topologiesについてまとめてみる
たまたま仕事でTeam Topologiesをまとめる機会があったので、備忘録がてらブログにしておく
Team Topologiesとは
Matthew SkeltonとManuel Paisによる本
DevOpsの視点から高速なDeliveryを実現するためにどのようなチームや組織を作るべきかをまとめてる本
チームをDeliveryの最も重要な単位として(Team first-thinking)、チームのパフォーマンスが最大になるようにチームの人数やその責任の範囲の作り方(Team API)から、基本的なチームタイプ(Fundamental team topology)やそのチーム間のコミュニケーション(Team interaction mode)が紹介されてる
コンウェイの法則
システムを設計する組織は、そのコミュニケーション構造をそっくりまねた構造の設計を生み出してしまう
逆コンウェイ戦略
コンウェイの法則に逆らわず、 理想のアーキテクチャを実現するためにそれにあった組織やチーム構造にする
Team first-thinking
小さく長期的に安定したチームを作ることが非常に重要
小さいチーム
小さくの単位は具体的には5-9人
この根拠はDunbar's number
これは人間が安定的な社会関係を維持できるとされてる人数の認知的な上限
チームの人数が増えるとコミュニケーションのパスの数が増える
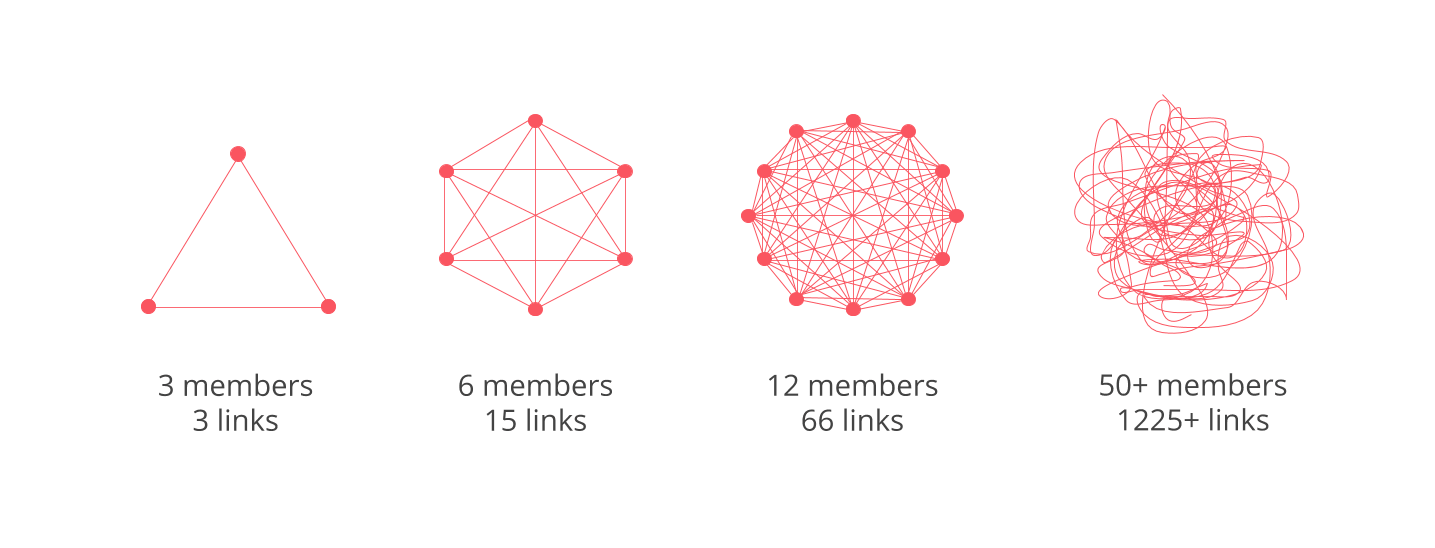
https://blog.nuclino.com/two-pizza-teams-the-science-behind-jeff-bezos-rule
認知負荷
チームの責任範囲をチームが扱える認知負荷に合わせたものにする
認知負荷を超えたチームは集団志向ではなく個人志向で振る舞うようになる
Ownership
また、チームがOwnershipを持てるようにする
プロダクトの目的の維持とそのための継続的な運用を考えられる
複数のチームが同一のシステムやサブシステムに修正を許すとだれもOwnershipを持たなくなる
Team API
チーム間の良い相互作用を作るためにチームをAPIとして考える
チーム間の依頼のIFをしっかり定義して非同期的な動きができると良い
また、Team APIをしっかりと定義するとよい
テンプレートは下記
Fundamental Topologies
役割の曖昧な複数のタイプのチームがあると責任の所在がわからなくなる
「Team Topologies」が提唱してるのは下記4つのチームに制限すること

基本的にStream aligned teamが根幹で、それ以外の3つのチームがStream aligned teamの負荷を軽減する
Stream aligned team
- ビジネスにおいて1番重要なチーム
- ビジネスドメインに沿った開発を行う
Enabling team
- 機能開発で時間がないチームに対して新技術やプラクティスの導入を支援していくチーム
- 複数のStream aligned teamを横断的に支援
- 適切なツール、プラクティスの調査、提案
- 実作業でなくガイダンスの提供、短期的な支援
- 永久にそのチームにいるわけではなく一時的な支援(自立支援)
Complicated sub-system team
- 専門知識が必要な複雑なサブシステムを開発運用するチーム
- たとえばクレジットカードのプロセッシング、画像や動画の配信部分、AIや機械学習など
- 目的はStream aligned teamの認知負荷を下げること
- Stream aligned teamがブラックボックスとしてそのシステムを扱えるようにすること
Platform team
- インフラ周りや共通基盤、ObservabilityやDeliveryを提供するチーム
- これによりStream aligned teamの認知不可を軽減する
- Developer Experienceを最重視
- Stream aligned teamの邪魔にならないように
- 最低限でシンプルなものにする
- なんでもかんでも提供すればいいってもんでもない
- 認知負荷の増大につながる
Team firstな境界
目指すべきは分離が容易な疎結合
チームの認知負荷に合わせてソフトウェア境界を選ぶ
素早いDeliveryを実現されるにはStream aligned teamが単一のドメインにたして責任をもつのが単純で手っ取り早い
疎結合にしていくにはモノリスがあることを認識することが重要だが、モノリスにも種類がある
モノリスの種類
- アプリケーションモノリス
- 複数の依存関係をもつ単一で巨大なアプリケーション
- データベースモノリス
- 同一DBのスキーマと結合している複数のアプリケーション
- モノリシックビルド
- 単一のCIでビルドを行う
- コードベース全体でのビルド
- モノリシックリリース
- すべてのコンポーネントをまとめて同一環境に導入しなくてはいけないリリース
- モノリシックモデル
- 単一のドメインや表現を多くのコンテキストで強制する
- モノリシック思考
- 単一のスタックやツールを強制
- Ownershipが保たれずモチベが低下する要因になる
- モノリシックワークスペース
- 1人ずつ隔離されたスペース
境界を見つける
節理面をさがす
Team Interaction Mode
それぞれのチーム間のインタラクションは下記
- Collaboration
- 他のチームと一緒に働く
- コラボにより摩擦は発生する
- X-as-a-Service
- コラボレーションを最小にしてツールやAPIを提供する
- Stream aligned teamとPlatform team
- Facilitation
- 他のチームの補助
- Stream aligned teamとEnabling team
さいごに
開発生産性を向上させるためにチーム構成を考えることも重要
ただ、組織に正解はないと思うので、自分達にあったものを取捨選択していくことが大事
そのためには先人の知恵を知っておくことも重要
参考情報
- https://amzn.asia/d/f0l0NBR
- https://blog.nuclino.com/two-pizza-teams-the-science-behind-jeff-bezos-rule
- https://engineering.mercari.com/blog/entry/20210812-team-topologies-in-souzoh/
- https://deeeet.com/writing/2020/02/06/team-topologies/
- https://github.com/TeamTopologies/Team-API-template
- https://teamtopologies.com/
Fixing For Loops in Go 1.22
今更ですが、年明けに社内のGo勉強会で登壇した時の資料を置いておきます